In the good old days of small data, businesses relied on sampling and demographics in their marketing and advertising campaigns. For example, a survey of a small sample of the residents within a particular geographic area (such as within a specific zip code) would indicate a certain distribution of people by age, gender, income level, education completed, etc. The demographic distribution within this small sample was assumed to be representative of the whole population in that area. Therefore, when marketing and advertising campaigns were deployed, it was generally a single campaign directed at and crafted for that representative demographic distribution.
If the business tried a bit harder to segment their campaigns, then they would still create segments (i.e., clusters) of multiple individuals with similar characteristics. Consequently, if I was a white male over the age of 50 with a college education, then I would get the same targeted ads as all other members of the population in that segment. There was no specificity with regard to likes or preferences. So, if I happen to like college football games, and my neighbor (in the same segment by age, gender, and zip code) happens to like indie music concerts, then we would still receive the same promotions.
This is not very helpful for the business nor for the consumer.
Clusters (segments) that bunch together many diverse members who happen to share a few attributes in common will almost certainly fail to capture the most important distinguishing characteristics of the individuals within the population. For example, if you are offered two unlabeled bags of white crystalline powder at a store, and you are told that one of them is salt and the other one is sugar, but you have to buy the whole bag in order to figure out which one is the sugar (and which one is the salt), then you have just experienced the problem with demographic-based segmentation (clustering). It is based on an insufficient number of features (color, texture, appearance), and it entirely omits the one key feature that distinguishes the two members of the population (taste!).

Divisive Clustering
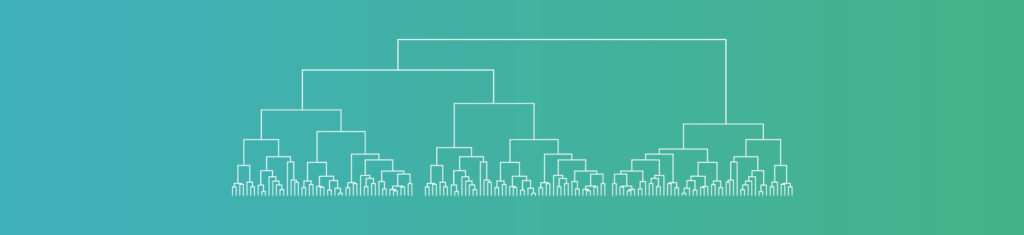
In data science, there is a technique known as divisive clustering that helps to solve this problem. No, “divisive” does not refer to hostility or disagreement between individuals causing them to separate into different camps. Rather, divisive clustering refers to a process known as “top-down clustering”. In this algorithm, a sample of items is recursively subdivided into smaller and smaller clusters.
Initially, all items in the sample are in a single cluster. Then, items are divided into two (or more clusters) based on the value of one particular attribute (such as age, or gender, or income level, or number of children). Then each of those clusters is divided into smaller clusters based on the value of another attribute. This process continues, iteratively selecting a different attribute to subdivide the clusters at a given level, until finally (at the end of the process) each member of the population is in a cluster of its own. These are called singleton clusters.
In the world of marketing, this is referred to as a “segment of one”. That one has specific preferences, likes, tastes, desires, wishes, etc. that make it different from every other singleton cluster. A business marketing campaign, or coupon offer, or ad can then be specifically targeted to that one person.
That is divisive clustering – dividing the population of N members recursively from one cluster of N members step-by-step until you end up with N clusters with one member each. For this reason, the era of big data is sometimes referred to as “the end of demographics.”
Two useful aspects of the segment of one (divisive clustering) in the world of marketing analytics are: (1) the customer may reside in a different cluster at different times of day, in different contexts (at work, or at home), on different days of the week, at different locations (at a grocery store, or at the mall, or at the music store); and (2) you don’t need to design N*M marketing campaigns (for N customers in M different contexts), since it is very reasonable to assume that different segments will respond favorably to the same campaign, depending on time, location, and context.
Therefore, divisive clustering is a valuable analytics approach that enables your marketing campaign to achieve the desired level of personalization and “segment of one” that will ultimately enhance individual customer experience, improve customer loyalty, drive conversions, and increase your business revenues.
For more from Kirk Borne, follow him on Twitter: @kirkdborne
Blog post originally published: July 23, 2014